安全的伪随机数生成

实验概述和内容
在安全软件中,生成随机数是一项非常常见的任务。在许多情况下,加密密钥
不是由用户提供的,而是在软件内部生成的。它们的随机性非常大重要;否则,攻击者可以预测加密密钥,从而挫败加密的目的。许多开发人员知道如何从他们的数据库中生成随机数(例如用于蒙特卡罗模拟)所以为了安全起见,他们使用类似的方法来产生随机数。不幸的是,一个随机数序列可能有利于蒙特卡罗模拟,但他们可能是对加密密钥不利。开发人员需要知道如何生成安全的随机数,否则他们会犯错误。类似的错误也出现在一些知名产品上,包括网景和Kerberos。
学习为什么典型的随机数产生方法是不适当的用于生成秘密,如加密密钥。他们将进一步学习生成伪有利于安全的随机数。本文涵盖以下主题:
- 伪随机数生成
- 随机数生成中的错误
- 生成加密密钥/dev/random和/dev/urandom设备文件
实验室环境
- 本实验室已经在SEED Ubuntu 20.04虚拟机上进行了测试。你可以下载一个预建的
映像,并在您自己的计算机上运行SEED虚拟机。然而,大多数种子实验可以在云上进行,您可以按照我们的说明在云上创建一个种子虚拟机
1、以错误的方式生成加密密钥
如果在Linux上运行的话,可以使用gcc命令编译time_random.c 并运行,这里我从课程中python实现换成C语言重新实现了一遍,当然随机数生成过程是一样的。
代码实现:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define KEYSIZE 16
void main()
{
int i;
char key[KEYSIZE];
printf("%lld\n", (long long)time(NULL));
srand(time(NULL));
for (i = 0; i < KEYSIZE; i++)
{
key[i] = rand() % 256;
printf("%.2x", (unsigned char)key[i]);
}
printf("\n");
}
执行运行命令,输出到time_random。
gcc time_random.c -o time_random
./time_random
多次执行 ./time_random 文件几次,就会随机生成不同的结果:
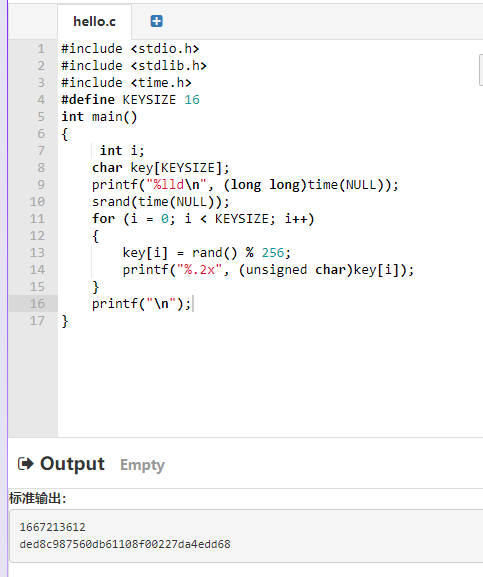
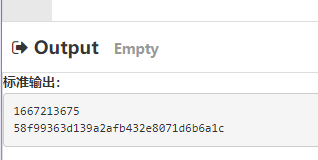
因为他使用的是当前的时间来当作随机数的种子,所以生成不同的随机数,肯定会保证得到不同的随机,因为每一次运行的时间都不一样。
如果我们尝试注释这一行代码srand(time(NULL));,然后选择重新编译和运行他,那么现在生成的随机数就变成一样的了。
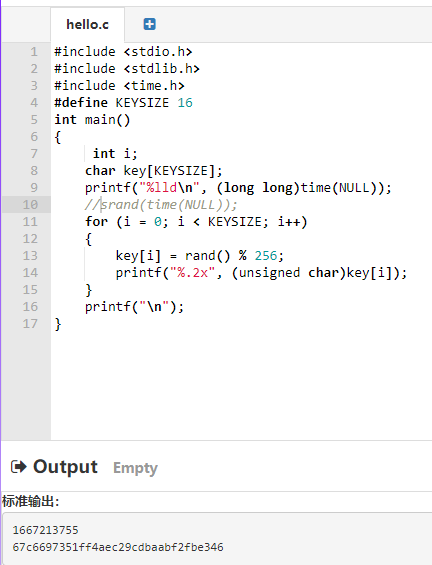
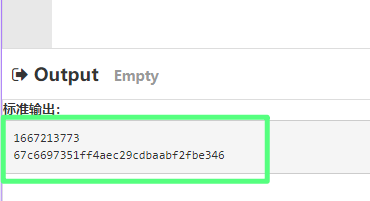
2、密钥预测和猜解
通过下面的命令获取时间的数量表示2022-10-20 02:08:49,离1970-1-1的时间总数。
date -d "2022-10-20 02:08:49" +%s
它返回166720231。
然后,我们在其中的第12行前添加一个循环,将time_random.c在两小时内生成的所有可能的随机数列为time_guess.c:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define KEYSIZE 16
void main()
{
int i;
char key[KEYSIZE];
for (time_t t = 1524020929 - 60 * 60 * 2; t < 1524020929; t++) // within 2h window
{
srand(t);
for (i = 0; i < KEYSIZE; i++)
{
key[i] = rand() % 256;
printf("%.2x", (unsigned char)key[i]);
}
printf("\n");
}
}
获取所有的输出到文本文件中保存:
gcc time_guess.c -o time_guess
time_guess > key_dict.txt
在key_dict.txt中使用暴力破解编写一个guess_key.py程序来生成所有的密文与实际的密文依次比对出一模一样的那一个。
源代码如下:
#!/usr/bin/python3
from Crypto.Cipher import AES
data = bytearray.fromhex('255044462d312e350a25d0d4c5d80a34')
ciphertext = bytearray.fromhex('d06bf9d0dab8e8ef880660d2af65aa82')
iv = bytearray.fromhex('09080706050403020100A2B2C2D2E2F2')
with open('key_dict.txt') as f:
keys = f.readlines()
for k in keys:
k = k.rstrip('\n')
key = bytearray.fromhex(k)
cipher = AES.new(key=key, mode=AES.MODE_CBC, iv=iv)
guess = cipher.encrypt(data)
if guess == ciphertext:
print("find the key:", k)
exit(0)
print("cannot find the key!")
成功找出key:
$ chmod u+X guess_key.py
$ guess_key.py
find the key: 95fa2030e73ed3f8da761b4eb805dfd7
3与4、测量核的熵以及获取random
cat /dev/random | hexdump
这是设备中熵与随机数的生成但是这样的输出很慢,如果保持不动时几乎不会生成。使用命令可以在另一个终端中监控熵值的生成:
watch -n .1 cat /proc/sys/kernel/random/entropy_avail
当我移动鼠标或输入某些内容时,该值会快速增加。
每减少一次,就会出现一行新的随机数。
所以我们可以说,/dev/random使用了用户行为产生的可用熵来生成新的随机数。
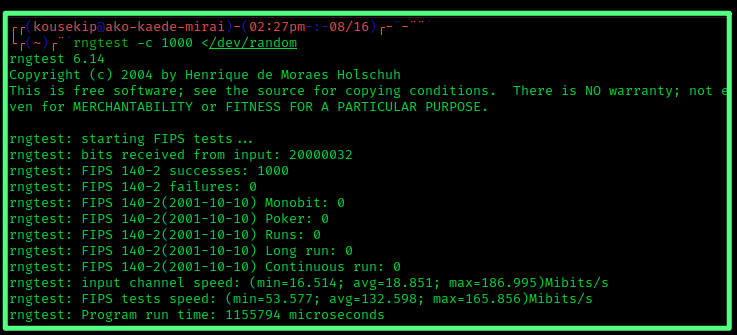
如果服务器与客户端使用/dev/random生成随机会话密钥。
在攻击者不断拒绝服务(DOS)攻击的过程中请求建立连接,导致服务器用完了/dev/androm的可用信息量,则随机数生成器被阻止。
5、学习使用urandom
cat /dev/urandom | hexdump
它一直在打印随机数字,所以我打算将前1MB数据量的输出截断保存为output.bin的文件:
head -c 1M /dev/urandom > output.bin
然后使用ent评估其信息密度,即熵的大小:
ent output.bin
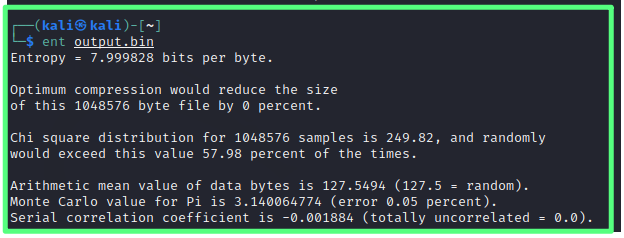
在大多数情况下,他已经足够随机了,满足大多数随机性要求。
使用系统文件 /dev/urandom生成一个大小为 256比特的随机数文件,并把他作为回话session密钥,使用在程序 read_random_key.c中
#include <stdio.h>
#include <stdlib.h>
#define LEN 32 // 256 bits
int main()
{
unsigned char *key = (unsigned char *)malloc(sizeof(unsigned char) * LEN);
FILE *random = fopen("/dev/urandom", "r");
fread(key, sizeof(unsigned char) * LEN, 1, random);
fclose(random);
printf("k = ");
for (int i = 0; i < LEN; i++)
printf("%.2x", key[i]);
printf("\n");
return 0;
}
编译文件:
gcc read_random_key.c -o read_random_key
执行输出:



